Die Startseite null konnte nicht in Bereich Installation alt gefunden werden.
Einleitung
Ab der Nuclos Version 4.4 steht der Cluster Betrieb zur Verfügung.
Mehrere Nuclos Server lassen sich in einem Cluster betreiben. Somit wird die Ausfallsicherheit erhöht.
Dabei verwenden alle Server Instanzen die gleiche Datenbank. Als Grundlage dient das Ticket NUCLOS-1815 - Abrufen der Vorgangsdetails... STATUS
Das Szenario sieht vor das ein Dispatcher/Load Balancer zwischen den Nuclos Client's und Nuclos Server's wirkt.
Dieser ist nicht Bestandteil einer Nuclos Auslieferung.
Installation
Während der Installation kann der Administrator in der Server Konfiguration den Cluster Betrieb ein-/ausschalten.
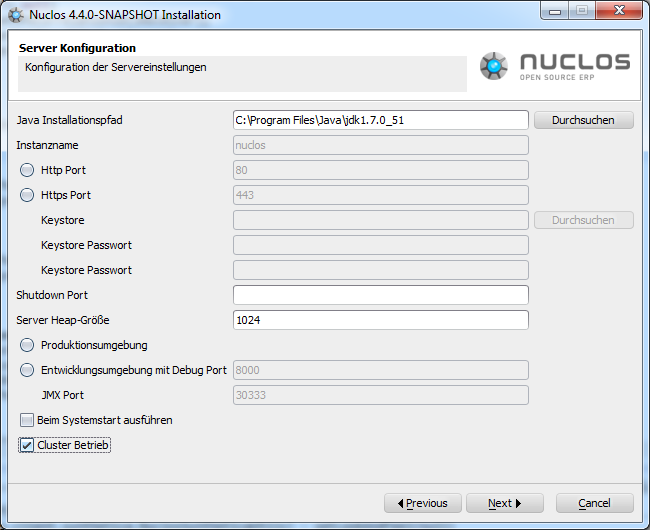
In der Datei ${NUCLOS_HOME}/conf/server.properties und in der ${NUCLOS_HOME}/nuclos.xml wird die Konfiguration festgeschrieben.
Property in server.properties: cluster.mode=false || true
Der erste Server fährt hoch
Während des Autosetup's von Nuclos wird die Tabelle T_MD_CLUSTER_SERVER erstellt. In dieser Tabelle registrieren sich alle Server,
die im Cluster Betrieb sich mit dieser Datenbank verbinden. Der erste Server der sich anmeldet ist der sogenannte Master.
Nur der Master startet den Quartz Scheduler. Somit laufen alle Nuclos Job's auf ihm.
Beendet sich ein Server, nimmt er seinen Eintrag aus der Tabelle heraus.
Kommunikation untereinander
Alle relevanten Nachrichten werden per JMS an die angemeldeten Server verteilt.
Das betrifft die Server-Seitigen Caches, die Regel-Kompilierung, etc.
Ist ein Client-Seitiger Cache betroffen, wird der Client, der mit einem bestimmten Server verbunden ist ebenfalls aktualisiert.
Ausfall eines Server's (Master)
Fällt ein Server aus, physikalisch oder die Java Virtual Machine wird abgebrochen, kann er den Eintrag nicht selbstständig aus der Tabelle T_MD_CLUSTER_SERVER herausnehmen.
Alle Server schauen in einem regelmäßigen Zeitabstand nach, ob noch alle angemeldeten Server erreichbar sind. Ist ein Server nicht mehr erreichbar, wird er aus der Tabelle entfernt.
Fällt der Master aus und die anderen bemerken diesen Umstand, wird über das Strategie Pattern ein neuer Master ermittelt. Dieser übernimmt die Job-Steuerung.
Die Strategie, die den neuen Master bestimmt, muss das Interface org.nuclos.server.cluster.NewMasterNodeStrategy implementieren.
Zur Zeit übernimmt der Server, der am längsten Online ist, siehe org.nuclos.server.cluster.OldestNodeStrategy.
Ausgeschalteter Cluster-Betrieb
Läuft der Server nicht im Cluster-Betrieb, erfolgt kein Eintrag in die Tabelle T_MD_CLUSTER_SERVER.
Somit werden keine Nachrichten an andere Server verschickt.
Der Quartz Scheduler für die Hintergrund Jobs wird während des Server-Start gestartet.
Änderungen an Nuclos
- Alle Caches müssen bei Invalidierung den gleichen Vorgang auslösen.
- Bei den eigenen Caches, z.B. ServerParameterProvider wurde das Interface org.nuclos.server.cluster.cache.ClusterCache implementiert.
- Die Spring konfigurierten Caches werden im Cluster Betrieb dekoriert, siehe org.nuclos.server.cluster.cache.NuclosSimpleClusterCacheManager
Im Cluster Betrieb reichen sie die entsprechende Aktion zentral weiter.
- Im Cluster Betrieb darf nur der Master den internen Quartz Scheduler starten.
- ...
Was fehlt noch
- Eine Maske im Client, die alle angemeldeten Server auflistet. Aktionen der Maske:
- Beenden eines Servers
- Server zum Master-Server erheben
- Server pingen (alive Test)
- ...
Überblick
Inhalte